Preliminary Thoughts About a Practical Synthetic 4DGS Pipeline

(Special thanks to Nick Porcino for valuable help and reality-checking these intuitions!)
Dynamic Volumetric capture and 4D Gaussian Splatting remain some of the most exciting (and frustrating) corners of real-time graphics right now. As I continue experimenting with synthetic capture workflows, a few practical observations keep surfacing.
-
The first major distinction seems to be “flipbook” playback versus temporally-coherent 4DGS representations.
A flipbook approach - that is, effectively training or storing independent splat reconstructions per frame - is comparatively understandable and interoperable, but comes with enormous storage and runtime costs. From a VFX perspective, think of it as the "Alembic Cached Animation" of splats. Static information gets duplicated across frames, performance degrades rapidly, and the resulting datasets become unwieldy very quickly. At the time of writing Playcanvas has a great flipbook example - notice its stop-motion qualities; you can tell it's a bunch of splat frames rendered sequentially (still rather impressive, of course, especially on the web.)
Learned 4DGS approaches, meanwhile, promise temporally coherent representations and dramatically better playback characteristics, but at the cost of substantially more complex training pipelines, weaker interoperability, and a tooling ecosystem that still feels highly experimental. There is no obvious “OpenUSD for 4DGS” yet, nor broadly standardized authoring, interchange, or playback infrastructure. There are too many papers and approaches to do them all justice here (and SIGGRAPH 26 hasn't even happened yet, woof) - the "canonical" paper describing this approach is, arguably, 4D Gaussian Splatting for Real-Time Dynamic Scene Rendering. It's worth a read, or at least a watch. One key sentence is "a lightweight MLP is applied to predict Gaussian deformations at novel timestamps" - this is a terrible analogy, but consider splats like bones in a rig/skeleton, wherein splats mostly persist over time, and their position can be predicted not unlike the process of determining the transform of a bone given its timestamp. This, of course, is night and day from splat-per-frame, flipbook being the anim cache in this analogy.
(As a sidenote to this, I'm less interested in bespoke, productized rendering solutions - while I am a big fan of the likes of gracia and others, they are not the focal point of my current work because:
- they all seem to be mostly focused on live volumetric capture and playback (for lack of a better term for the opposite of that: in-DCC / render engine splatting)
- they usually lean heavily into end-to-end, closed-source, black-box, heavily productized proprietary pipelines. Which is very understandable! But (at least until my lance is no longer free-) my inquiries are focused on the state of the art, which tends to be informed by (and benefit from) generally available, often free, typically open sourced or at least very legally permissive work.)
-
Given this tradeoff, it increasingly seems reasonable to start my deeper exploration with a flipbook-style approach.
Even if the long-term destination is a more advanced learned representation, the immediate practical problems remain the same: capture topology, camera coverage, synchronization, data organization, metadata generation, playback infrastructure, and automation.
Put differently: there is value in solving the pipeline mechanics first before chasing the more sci-fi aspects of efficient dynamic reconstruction.
-
Unfortunately, as far as I can tell there is currently a dire lack of tooling even within the capture / splatting niche itself.
Most existing synthetic splat capture tooling appears optimized for static scenes: a single camera moves through a scene over time, rendering sequentially while emitting transforms and imagery for reconstruction. Gauss Cannon, which I raved about in a previous post, does exactly that. Incidentally I started an issue in that repo, asking about/proposing a 4DGS approach, and the creator, Arash Keshmirian, provided an illuminating reply on twitter re. some of the Blender-specific challenges involved with that kind of adoption.
To clarify why this is an issue - this sequenced-single-camera-over-time approach breaks down immediately for dynamic capture, for hopefully straightforward reasons: In a 4DGS context, rendering camera A on frame 1 and camera B on frame 120 is meaningless if the subject itself has moved. The moment the camera traversal becomes temporally serialized, animation contaminates the reconstruction process.
Put simply: as the camera moves, so would the animation. You can see this in action on a static scene here: -

Again, this is obviously not a problem for 3DGS, but consider what happens when the timeline is actually used for animation!
Real volumetric capture systems inherently solve this through simultaneous multi-view acquisition. You've probably seen them before - they typically look something like this:

Ironically, many synthetic pipelines currently do the opposite because they inherit assumptions from offline rendering workflows rather than synchronized capture systems. If there's no animation, there's nothing wrong with a single camera traversing the scene.
-
In light of this misalignment, building a bespoke synthetic 4DGS capture tool increasingly feels like the pragmatic direction.
Rather than traversing a single camera through time, such a system would instead enumerate many simultaneous cameras per animation frame, more closely resembling real-world volumetric capture rigs. It would probably look something like:
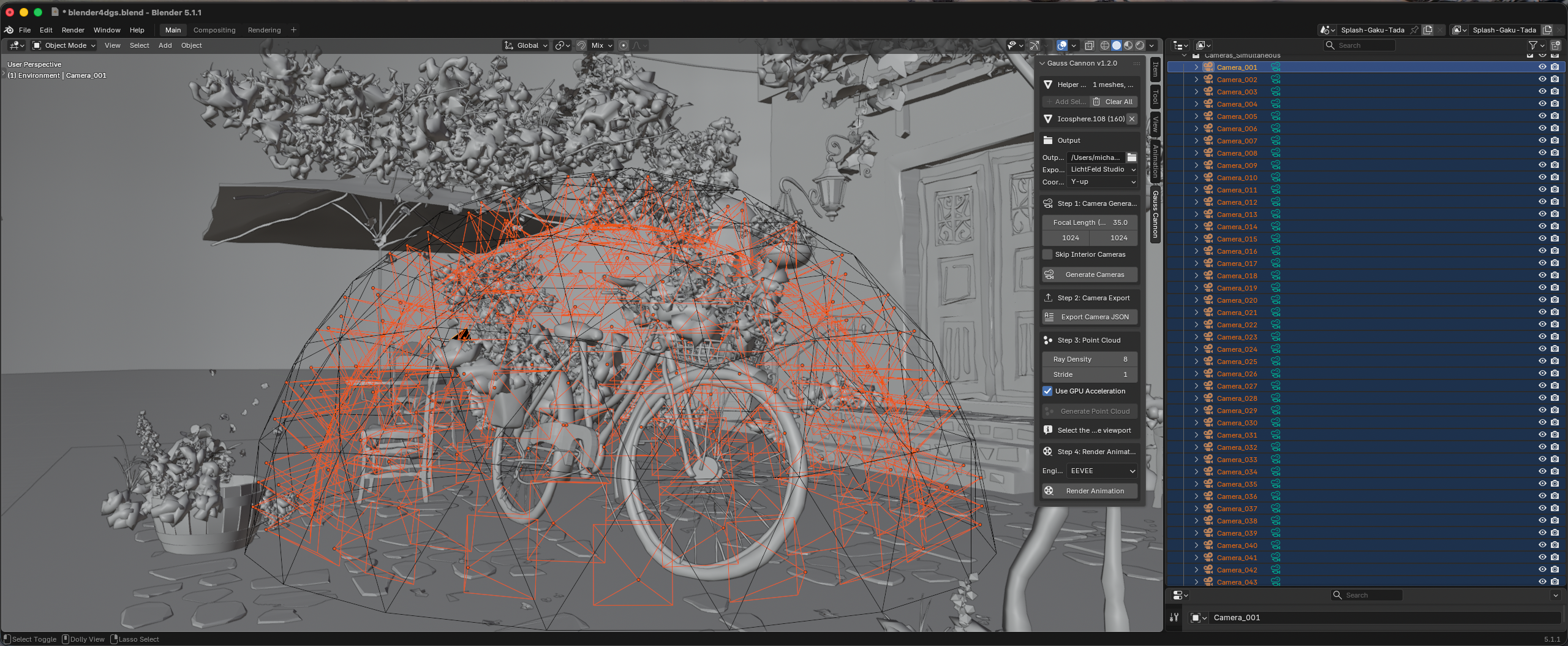
Wherein all viewpoints are represented by bespoke respective cameras, which stay put throughout the timeline. Just as in the real life example above.
Existing sequence rendering infrastructure could still do much of the heavy lifting, but the orchestration model would fundamentally change from:
“one camera over many frames”
to:
“many cameras per frame.”
Which is probably the single biggest paradigm shift such a tool would have to accommodate.
-
Such a system would likely need to emit per-frame extrinsics and, ideally, point cloud data as well. (Incidentally the new ImagePlanes schema in OpenUSD (25.08) is ideal for recording intrinsics and extrinsics, and designed for purposes such as photogrammetry.)
For flipbook-style approaches, generating a point cloud per frame seems necessary, since each frame effectively behaves like an independent reconstruction problem.
More advanced learned 4DGS systems may ultimately require less redundant geometric initialization. A canonical point cloud representation helps establish temporal coherence and stabilize optimization across time, rather than requiring fully independent geometry reconstruction every frame.
That said, this remains an active area of exploration, and the exact balance between explicit geometry priors and learned temporal representations is still evolving rapidly across the field.
These are just a few early, scattered thoughts as I continue my study of this domain and plan my next steps. I am documenting them here in the hopes of (among other things) having more, and better, conversations around this highly specialized area. If you are working on similar problems and want to chat, please reach out!
Twitter / X: @michaelybecker
email: hello (at) michaelybecker.com